< 목차 >
0. TL;DR
1. 이진수와 2의 보수법
2. 부동 소수점
3. 문자 인코딩과 디코딩
0. TL;DR
- 이진수: 모든 양수를 0과 1로 표현하는 방법
- 2의 보수: 모든 음수를 0과 1로 표현하는 방법
- 부동 소수점: 모든 소수(분수)를 0과 1로 표현하는 방법
- 문자 집합 & 인코딩: 모든 문자를 0과 1로 표현하는 방법
들어가며
컴퓨터는 0과 1만을 이해한다.
데이터가 컴퓨터 내에선 어떠한 방식으로 표현이 되는지 알아보자.
이진수, 2의 보수, 부동 소수점, 문자 집합과 인코딩에 대해 중점적으로 살펴볼 것이다.
참고로,
‘문자 집합’은 컴퓨터가 이해할 수 있는 문자들의 모음이다.
‘인코딩’은 문자 집합을 이용해서 0과 1로 변환하는 과정이다.
1. 이진수와 2의 보수법
- 이진법: 0과 1로 모든 수를 표기하는 방법
- 이진수: 0과 1만으로 표현된 수
- 1을 넘어가는 시점에서 자리 올림

우리가 일상적으로 사용하는 숫자는 십진법, 즉 ‘십진수’이다.
이진수의 단점
: 숫자가 너무 길어짐
그래서 이진수로 표현할 때는 십육진수로 표현할 때도 많다.
십육진법(십육진수)
: 1~9와 A~F로 모든 수를 표기하는 방법

- 십육진수: 1~9와 A~F로 표현된 수
- 15(F)를 넘어가는 시점에 자리 올림
A == 10, B == 11, C == 12, D == 13, E == 14, F == 15
십진수를 사용하지 않고 십육진수를 사용하는 이유는
십육진수와 이진수 간의 변환이 편해서다. 16진수는 2의 제곱승으로 표현할 수 있기 때문이다.
2의 보수법
: 0과 1만으로 음수를 표현하는 방법 중 하나
모든 0과 1을 뒤집은 뒤, 1을 더한 값이다.

그럼, 0과 1만으로 음수를 표현하면 양수/음수를 구분하기 어렵지 않을까?
양수인지 음수인지는 CPU 내부의 ‘플래그 레지스터’를 통해 판단한다.
- 플래그(Flag): CPU가 명령어를 실행하는 과정에서 참고할 정보의 모음
- 음수 플래그가 세팅된 경우: 음수
- 음수 플래그가 세팅되지 않은 경우: 양수
2. 부동 소수점
: 컴퓨터 내부의 소수 표현 방식(부동 소수점 표현 방식)

이진수를 m x 2^n 꼴로 나타낸다.
n에는 바이어스(bias) 값이 더해져 저장된다. 바이어스 값은 2^(k-1)-1 (k는 지수의 비트 수)
가수 부분은 1.xxx 꼴을 띈다. xxx(소수) 부분만 저장하면 된다.

프로그래밍 언어로 0.1 + 0.2(소수)를 계산했을 때 0.3이 나오지 않는다.
이러한 문제는 왜 생기는 것일까?
십진수 소수를 이진수로 표현할 때, 십진수 소수와 이진수 소수 표현이 딱 맞아떨어지지 않을 수 있다.
예시를 들면,
- 1/3이라는 분수 m x 3^n 꼴로 표현하면 딱 떨어진다.
- 1/3이라는 분수 m x 10^n 꼴로 표현하면 딱 떨어지지 않아서 무한히 많은 가수가 필요하다(0.33333… 처럼). 그래서 일부 가수는 버릴 수밖에 없기 때문에 오차가 발생할 수 있다.
3. 문자 인코딩과 디코딩

- 문자 집합: 표현 가능한 문자들의 집합
- 인코딩: 사람이 이해하는 언어 → 컴퓨터가 이해하는 언어로 변환
- 디코딩: 컴퓨터가 이해하는 언어 → 사람이 이해하는 언어로 변환

문자가 깨지는 문제는 ‘컴퓨터가 이해할 수 없는 문자 집합을 사용’했거나 ‘호환되지 않는 인코딩 방식으로 데이터를 읽어들여서’ 생겼을 확률이 크다.
아스키 코드 (ASCII code)
: 초창기 문자 집합으로, 알파벳 + 아라비아 숫자 + 일부 특수문자 + 제어 문자

위 표에서 함께 묶여있는 수와 문자는
각각 대응되게 인코딩 및 디코딩 된다.
이해하기 편하도록 예시를 들어보면 다음과 같다.

십진수 97을 문자로 변환했을 때엔 a가 나오고
문자 a를 십진수로 변환했을 때엔 97가 나온다.
유니코드 문자 집합
: 대부분의 언어 + 특수문자 + 이모티콘 + 화살표 etc
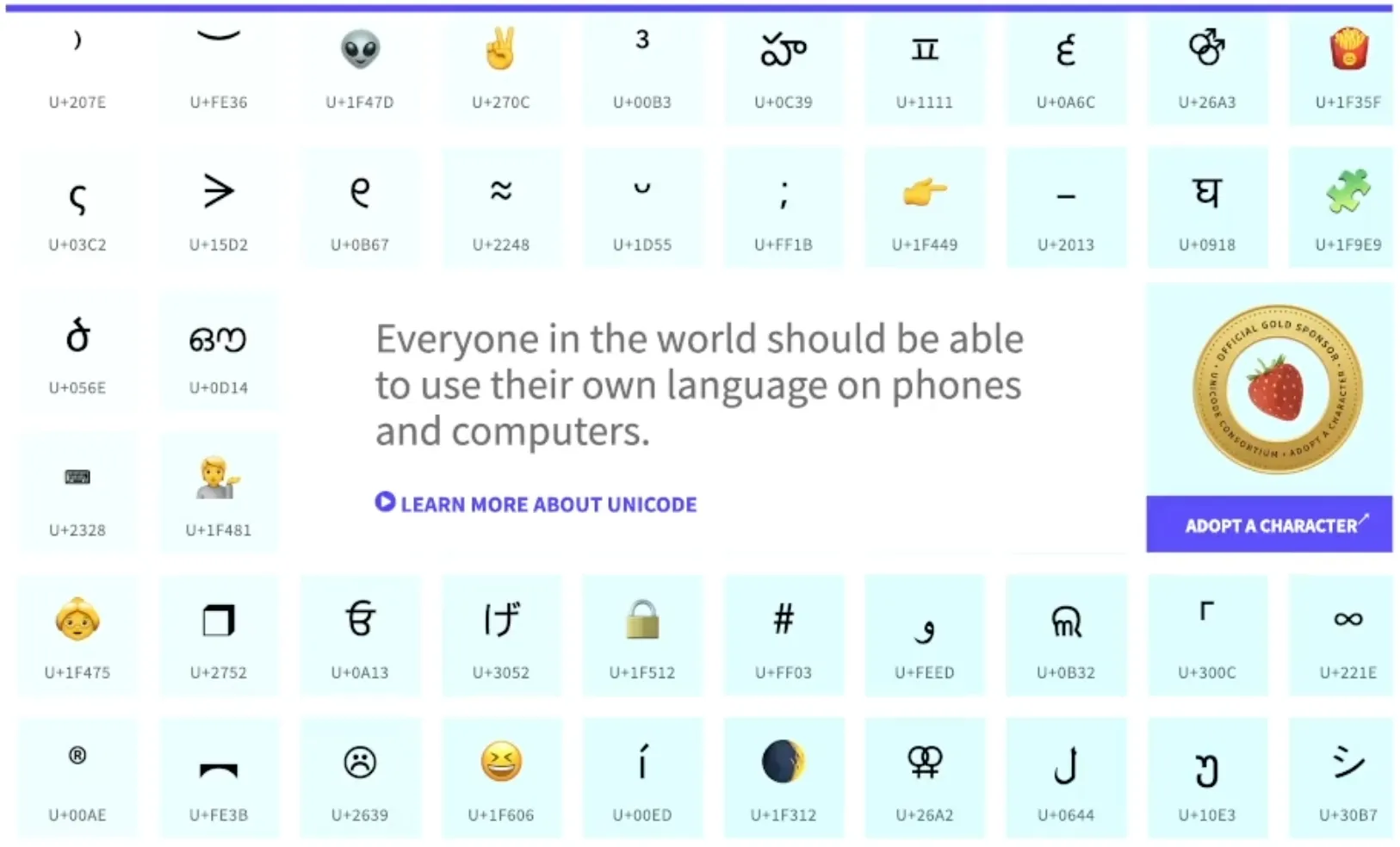
유니코드 코드 포인트: 유니코드 문자에 부여된 고유한 수
이 유니코드 사이트(http://home.unicode.org)를 참고해도 좋다.
아스키 코드는 대응해서 변환했지만,
유니코드는 같은 문자 집합이라고 할지라도 인코딩하는 방식이 다양하다.

코드 포인트를 인코딩하는 방식에 따라 utf-8, utf-16, utf-32 등으로 나뉜다.
이 사이트(https://codepoints.net)에서 코드 포인트가 맞는지 확인할 수 있다.
'CS (Computer Science)' 카테고리의 다른 글
| [개발 공부 116일차] 컴퓨터 구조 | 명령어 구조와 주소 지정 (4) | 2024.10.11 |
|---|---|
| [개발 공부 115일차] 컴퓨터 구조 | 컴파일, 인터프리트 (4) | 2024.10.10 |
| [개발 공부 114일차] 컴퓨터 구조 | 컴퓨터의 4가지 핵심 부품 (0) | 2024.10.09 |
| [개발 공부 112일차] DB 개론 | 성능을 고려한 데이터 모델링 (2) | 2024.10.03 |
| [개발 공부 111일차] DB 개론 | 데이터 모델링 문제 및 해소 (10) | 2024.10.02 |